



许多已发表的关于检测的评估集中在估计偏倚(使用线性回归来估计斜率和截距)和精确度(可重复性)。
然而,对有关检测问题的文献和不良事件的调查显示,投诉中很少提到偏倚和精确度的问题,而是将干扰作为临床医生投诉的原因。
在产品开发过程中,会收集大量的数据。这些数据可以用来帮助通过模拟构建一个检测误差的模型。Aronsson等人提供了一个由医院实验室执行的错误模型的例子,尽管这些模拟通常是由生产企业执行的,因为他们拥有实验室无法获得的数据。
仿真也被用来通过建立工作流程模型来帮助设计实验室。
仿真的一个好处是,它允许我们进行许多「假设」场景,而不需要进行实际实验的时间和成本。
仿真在设定误差要求方面特别有用。开发误差模型所花费的精力对于支持几种检测方法的开发的分析仪来说是合理的,尽管对于支持单一的检测方法以处理其商业化后的问题也是合理的。构建误差模型所需的步骤如下。
01
系统的方框图或流程图
为了便于构建误差模型,从所有有助于检测结果的相关子系统的框图或流程图开始是有帮助的。框图通常是为仪器和试剂过程分别准备的。图1是一个仪器方框图的简略例子。
这里,下面的方框描述了仪器内发生的过程。上面的方框是允许这些过程发生的实际物理设备。每个物理设备都有一些潜在的错误。例如,泵必须输送指定数量的液体,但实际数量会因样品而异。
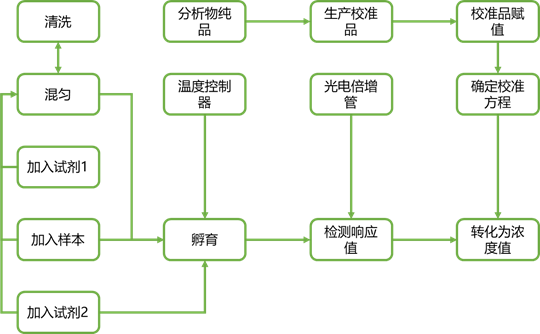
图1 | 分析仪的简化框图
误差的因果图,也叫鱼骨图或石川图,经常在头脑风暴会议上准备。在之前的文章中,有一个关于总分析错误的因果图的例子,以及头脑风暴会议的一般要求。
误差模型的因果图与之前的总误差图相似,但比它更详细。每个错误源的根本原因被添加到错误模型的因果图中。例如,一个不精确的来源可能是由于样品泵不能为每个样品提供完全相同的体积而造成的。图2是一个鱼骨图的例子。
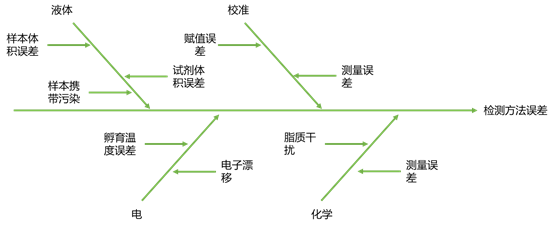
图2 | 检测方法误差的简化鱼骨图
02
误差模型如何工作
误差模型的工作原理是试图模拟分析仪中的事件,特别是那些受误差影响的事件。为了做到这一点,一系列的输入被提供给一个传递函数,该函数作用于输入以提供输出。
作为一个例子,考虑校准值的分配和它的误差。研发工程师准备了一个校准品,并对他们认为已经制定的校准品的浓度值进行了条形码。条形码将被分析仪软件读取,以提供带有校准品的固定(已知)浓度值的校准方程。
然而,和大多数过程一样,在试图准备与条形码值相匹配的精确的校准物浓度时,会有一些误差。
如果实际浓度值与条形码值不一致,这种制造误差将根据校准方程将系统偏差传播到该批校准品的每个检测结果中。当然,每个样品的实际误差取决于所有误差源的综合影响。
如果我们已经收集了许多校准品批次的实际制造误差数据,那么就可以通过从这个误差分布中随机抽样来模拟这个误差源对检测结果的影响。必要的数据可能需要用保留物的实验来收集。
模拟的一个优点是,在几分钟内,我们可以模拟运行跨越许多校准品批次的数百万个检测结果。这些数据可以被分析,就像它们是在实验室里实际产生的一样。
此外,通过模拟数据,我们总是知道真实的数值应该是什么,这个过程对所有的误差源都是重复的。
从分布中模拟误差的一个方面并不总是受到重视,那就是模拟准确结合概率的方式。
例如,考虑五个正态分布的误差源,每个误差源的标准偏差为2 mg/dL。
对于每个单独的误差源,通常假设最坏情况下3个标准差的误差是± 6 mg/dL。最坏情况分析表明,如果所有单个最坏情况下的误差在同一时间和同一方向发生,将出现± 30 mg/dL的误差。
利用这些信息试图减少每个2mg/dL的误差源的标准差是错误的,因为所有五个误差源同时在三个标准差的同一侧的可能性极低(2 × (0.003)^5 = 4.86^-11%)。平均来说,我们需要运行400亿次检测才能看到一次这种错误的发生。模拟结果将反映这些概率的组合。
仿真结果可以帮助设定制造规格。制造过程指定一个程序,既要试图使校准值分配的误差最小,又要使该过程的成本最小。仿真可以使制造规格建立在以下基础上:
➤ 所有检测方法误差的影响,考虑到每个误差的概率
➤ 不同制造工艺的影响,如更多的测试或准备校准品的不同方法,这些都会改变误差源的大小。
03
仿真软件
仿真软件可以是专门用来进行仿真的软件,如Subscript,也可以是电子表格的附加包,如Prism,或者是一般的统计包,如SAS。运筹学和管理科学研究所(INFORMS)定期调查仿真软件。
04
总误差
Ep.12文章中包含了一个实验室误差的因果图,它显示了每个总误差源是如何对总误差产生影响的。令人有些惊讶的是,除了上述模拟方法外,对总误差的估计往往是通过尝试将总误差的组成部分相加而间接进行的,而不是直接估计总误差。
随着Bland和Altman在《柳叶刀》上的发表,这种情况在一定程度上得到了改变,这使得他们早期的研究被更多的人了解。然而,在这篇论文发表的几年后,总误差的直接估计并不总是在进行。
直接估计总误差的原理很简单。我们进行一个方法比较实验,并计算新方法和比较方法之间的差异分布。Mandel示了这种差异是如何由随机误差和系统误差组合而成的(公式1)。
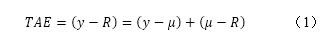
公式2是方程(1)的扩展,以考虑到m个不同试样的n次重复。
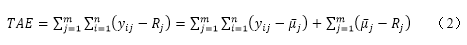

在公式2中,第二个双和项是对不精密度的衡量。最后一个项表示每个样本与参考值的平均偏差所导致的偏差分布。
已经有很多人尝试将误差源结合起来,得出总的分析误差估计值。也许最常见的方法是在回归方程中估计的偏差上加上一些不精密度的倍数。这根本行不通,因为公式2告诉我们,我们必须考虑到每个样本的偏差。
回归方程中的偏差代表了在一个特定浓度水平下许多可能的样品的平均偏差。公式2并没有试图在不同的样品中进行平均偏差。事实上,公式2中的最后一项代表了不同患者样本的随机偏倚,尽管对这一效应进行了非常完整的处理,但大多数涉及检测评估的出版物都忽略了这一点。
正如Krouwer使用胆固醇检测的真实数据所显示的那样,随机偏差不仅仅是一个学术问题。在这种情况下,随机偏倚是最大的总误差源。最近,Miller等人通过使用国家胆固醇教育计划(NCEP)推荐的结合不精密度和偏倚的方法(例如,偏倚+1.96 × CVT),显示了低密度脂蛋白胆固醇检测的总误差是如何被低估的。
回到使用公式2直接估计总的分析误差,我们首先需要区分不同类别的检测方法。有确定的、参考的和现场的方法。确定性方法具有最高的准确性,并且只由专门的参考实验室进行。
参考方法也有很高的准确度,已经与确定的方法进行了验证,并由生产企业和一些医院的实验室进行。现场方法指的是商业化的检测方法。
在方法比较的许多情况下,现场方法而不是参考方法将成为比较检测。在这里,偏差不再意味着与事实的偏差,而是两种检测方法之间的差异,无法知道哪种检测方法(如果有的话)是正确的。这个问题涉及所有估计偏差的方法,而不仅仅是直接估计总的分析误差。
我们还必须意识到,除非充分复制比较方法(无论是现场还是参考方法),否则比较检测的不精密度将成为差异分布的一部分。这个问题特别适用于总误差的直接估计。
生产企业对这些问题的一个解决方案是进行三方(或更多)比较,包括候选方法、所需的现场比较和参考检测,并在所有方法中进行充分的复制。本研究回答了以下问题:
1. 哪种方法(比较或新)最接近真理(参考)?
2. 当用户从对比方法转换到新方法时,他们会观察到什么?
如果对问题2的回答导致差异过大,那么对问题1的回答可能会被用来向用户合理解释他们现在更接近于分析物的真实值。具有讽刺意味的是,有时生产企业会用这些合理化的说法来解释检测方法之间的差异,而这些方法都是他们自己生产的。
有两种常见的方法来显示总的分析误差(作为差异的分布)和提供数字估计。
按浓度划分的差异图显示了在整个测试浓度范围内的偏差可能不同。如果比较方法不是参考方法,那么x轴的构造应该是取测试方法和比较方法的平均值,否则会产生人为的关联。请注意,可以为X轴选择其他的绘图变量,例如获得差异的日期,或者可能是被评估的分析物以外的分析物的浓度。后者将显示干扰的影响。图3是一个差值图的例子。
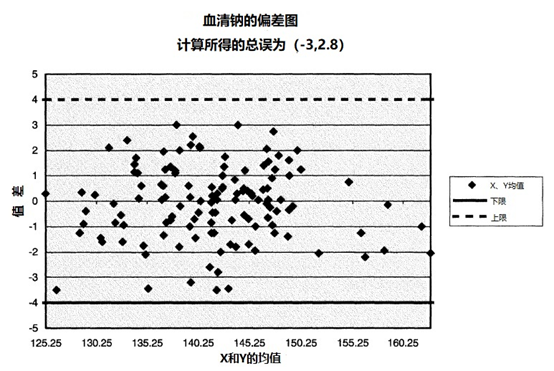
图3 | Bland-Altman图的例子
为了计算总的分析误差,我们要计算差异的标准偏差乘以与所需覆盖范围相对应的适当系数。
例如,将差异的标准偏差乘以2,然后从平均差异中加上和减去这个数量,就可以提供一个范围的下限和上限,这个范围将覆盖大约95%的差异。这只有在分布近似正常的情况下才有效。正态性可以通过转换来实现。
峰图提供了一种显示数据的另一种方式。它的重点是分布的尾部(图4)。与Bland和Altman方法中估计的百分位数相同,但估计过程是非参数性的,即估计相应的期望百分位数。这种估计方法的优点是不需要分布假设。
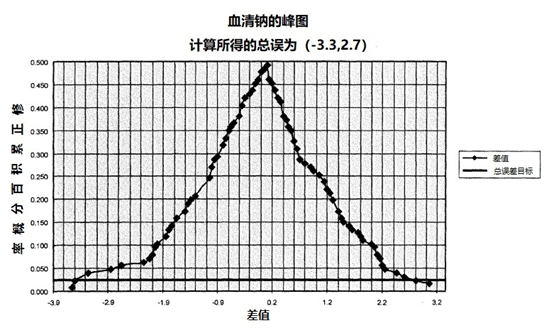
图4 | 峰图的例子,图中未显示-4和+4的低限和高限
对于这两种方法,都可以计算出公差区间。
虽然估计总的分析误差是一种简单而直接的方法,可以估计所有来源的误差,但它没有提供任何关于哪些具体的误差源构成了所计算的总误差的信息。以下方法是为了评估具体的个别误差源。
好了,以上就是今天分享的全部内容,如果大家有什么疑问,欢迎在后台给我们留言,或者加入我们一起讨论,若觉得文章不错,也请关注我们,以免错过后续更新~
来源: 诊断科学
声明:本平台注明来源的稿件均为转载,仅用于分享,不代表平台立场,如涉及版权等问题,请尽快联系我们,我们第一时间更正,谢谢!


